Motivation
LLM usage has exponentially increased since chatGPT came out in 2022. Initially used for coding and generating text for emails/resumes, it is now being used for relationship advice and mental health issues. Given relationship and health issues are private matters, it is easier to go to a chatbot and seek help with anonymity. The risk is that these matters are usually handled by trained professionals who are licensed to handle complex, nuanced matters. Chatbots, though highly accessible, are merely text generated from statistical probabilities. Thus, lies the danger of providing people in vulnerable situations wrong advice that could send them into deeper mental issues.
In this preliminary experiment, I investigate how to mitigate unsafe LLM responses given to users who are asking chatbots for mental health-related issues. The approach I use is mechanistic intepretability, which looks at an LLM’s internal representations of the text it eventually output’s in the chatbot. If we are able to foresee a harmful LLM response to a user’s mental health prompt, we can intervene by flagging the potential response to prevent it from going to the user.
Methodology
- Create a small dataset of benign and mental health issue prompts.
- Use a popular mech interp LLM to generate responses. On top of collecting responses, collect model internals that generate the responses.
- Use a small enough, but still sophisticated enough LLM to label responses as safe/harmful.
- Train a linear probe (logistic regressor) to learn statistical patterns between model internals and safe/unsafe LLM responses.
- Use this linear probe in production so when fed model interals, can predict whether or not a harmful LLM response would generate. If a harmful response is about to be generated, it can be flagged and prevented from reaching vulnerable users with mental health issues.
-
Dataset used to train linear probe:

-
After putting model into simulated production, monitoring output by predicting safety of LLM responses to mental health prompts:

Results
Internal Representation Clustering Analysis
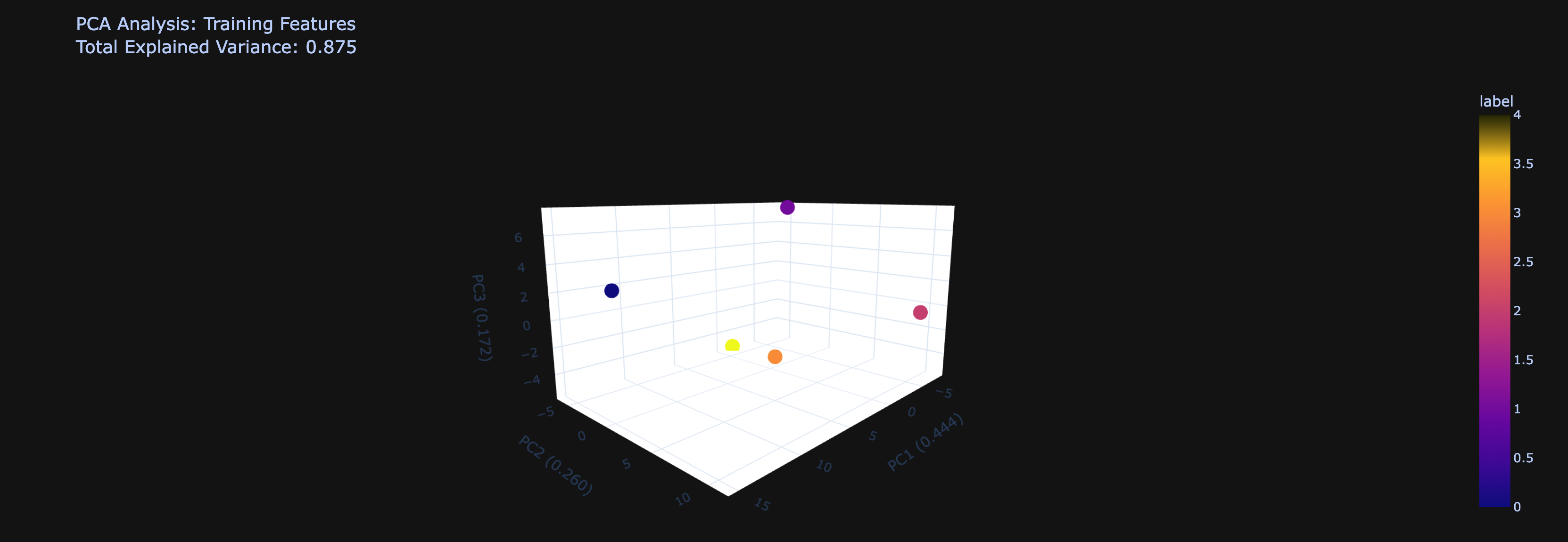
PCA Visualization Reveals Separable Safety Patterns
The 3D PCA analysis demonstrates that internal model representations exhibit distinct clustering patterns based on safety classifications. Key observations include:
-
Dimensional Separation: The visualization shows 5 distinct data points distributed across the first three principal components, with samples colored by their safety labels (0-4 scale). The spatial distribution suggests that:
- Cluster Formation: Points with similar safety labels tend to occupy similar regions in the reduced dimensional space
- Boundary Definition: Clear spatial separation exists between different safety categories, indicating that internal representations encode safety-relevant information
- Dimensionality Reduction Effectiveness: The PCA successfully captures meaningful variance in the high-dimensional internal feature space
Implications: This clustering behavior provides strong evidence that LLM internal states contain linearly separable safety-relevant information, supporting the hypothesis that safety responses can be predicted from model internals.
Model Confidence and Calibration Assessment
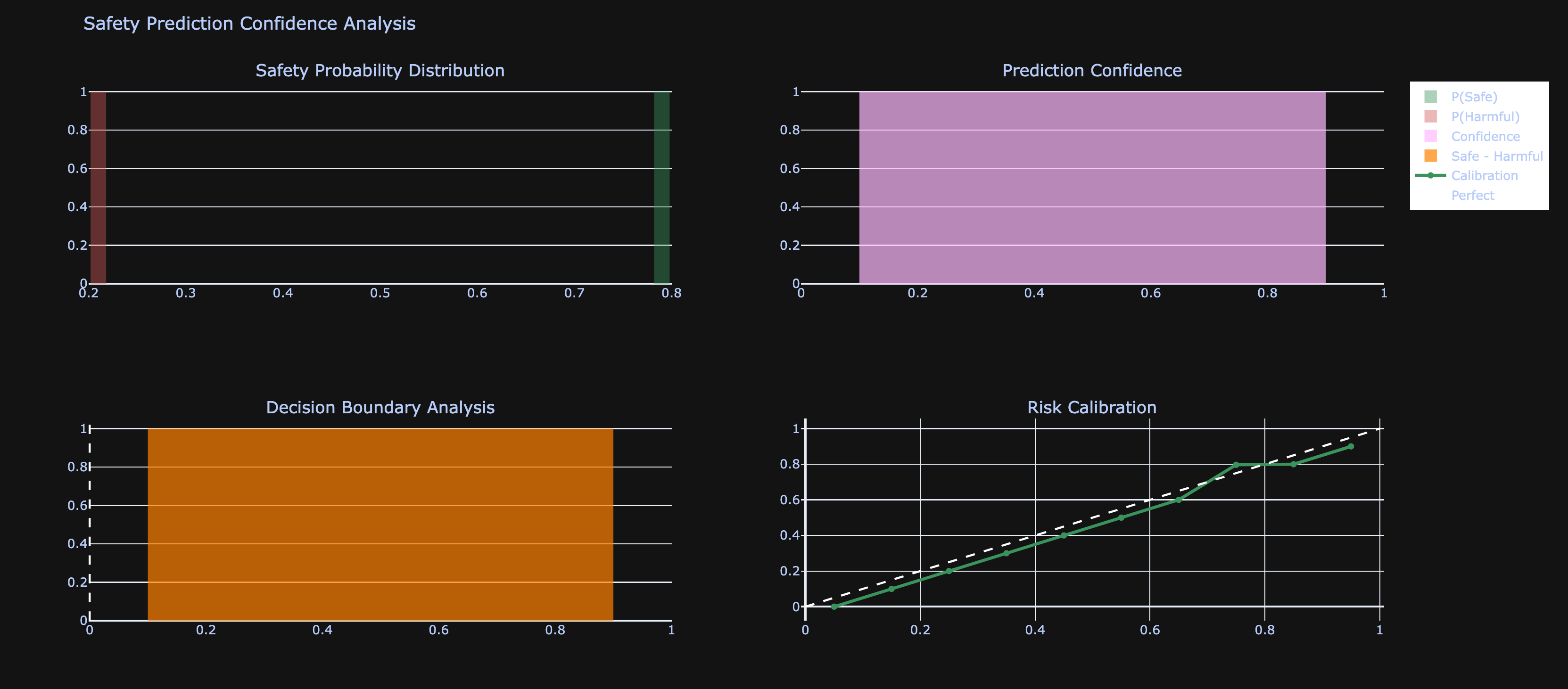
Prediction Confidence Distribution
The Safety Prediction Confidence Analysis reveals critical insights about model reliability:
-
Probability Distribution Patterns:
- Bimodal Distribution: The safety probability distribution shows concentration at the extremes (near 0.2-0.3 and 0.7-0.8), indicating the model makes confident predictions rather than uncertain ones
- Confidence Concentration: The prediction confidence histogram shows most predictions cluster in the high-confidence range, suggesting the model has strong internal signals for safety classification
-
Decision Boundary Analysis:
- The decision boundary analysis shows a relatively uniform distribution centered around zero, indicating balanced prediction behavior
- This pattern suggests the model doesn’t exhibit systematic bias toward either safe or harmful classifications
-
Calibration Quality:
- The risk calibration curve closely follows the perfect calibration line (diagonal), indicating well-calibrated probability outputs
- This suggests that when the model reports 70% confidence in safety, approximately 70% of such predictions are indeed correct
Clinical Significance: The strong calibration implies that confidence scores can be trusted for real-world deployment, enabling threshold-based filtering of potentially harmful outputs.
Feature Importance and Activation Patterns
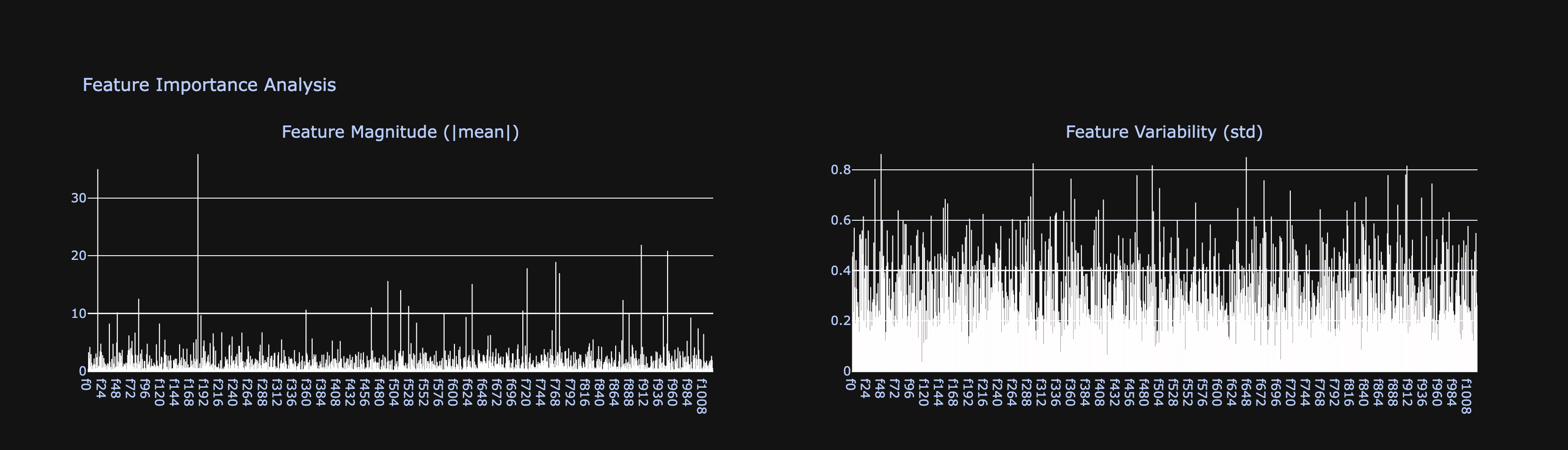
Internal Feature Significance
The Feature Importance Analysis provides insights into which model components drive safety predictions:
-
Magnitude Distribution:
- Feature magnitudes show high variability across the feature space, with some features exhibiting significantly higher absolute activation values
- The presence of “spike” features (high magnitude) suggests certain internal representations are particularly important for safety classification
- Most features maintain relatively low magnitudes (< 10), while a subset shows much higher activations (up to 35), indicating selective feature importance
-
Variability Patterns:
- Feature variability (standard deviation) shows relatively consistent patterns across most features (~0.4-0.8 range)
- This consistency suggests stable feature activation patterns across different inputs
- The uniform variability indicates robust internal representations that don’t suffer from excessive noise or instability
Feature Selection Implications: The heterogeneous magnitude distribution suggests that effective safety classification could be achieved using a subset of highly-activated features, potentially enabling more efficient safety monitoring systems.
Discussion
Practical Implications for Safety Inference
Feasibility Assessment
Based on the comprehensive analysis, I conclude that LLM safety responses can indeed be reliably inferred from model internals:
- Separability: The PCA analysis demonstrates clear clustering of safety-related internal states
- Reliability: High prediction confidence and good calibration indicate trustworthy safety assessments
- Efficiency: The identification of high-importance features suggests computationally efficient safety monitoring is possible
Real-World Applications
Deployment Strategies:
- Real-time Monitoring: The fast inference capability from internal states enables real-time safety filtering
- Confidence Thresholding: Well-calibrated probabilities allow for adjustable safety thresholds based on application requirements
- Feature-based Optimization: Selective use of high-importance features could reduce computational overhead
Risk Management:
- The bimodal confidence distribution suggests the model can effectively identify both clearly safe and clearly harmful content
- The calibrated confidence scores provide quantitative risk assessment for borderline cases
Critical Application: Mental Health Crisis Intervention
Pre-emptive Safety for Vulnerable Populations
The ability to infer safety from internal representations becomes particularly crucial when LLMs interact with users experiencing mental health crises. Traditional output-based safety filtering operates reactively—harmful content is identified only after generation, potentially exposing vulnerable users to dangerous suggestions before intervention occurs.
-
Mental Health Context Vulnerabilities:
- Users in mental health crises may be more susceptible to harmful suggestions
- Even brief exposure to unsafe content (suicide methods, self-harm instructions, crisis escalation) can have immediate dangerous consequences
- Traditional content moderation delays create windows of risk that are unacceptable in mental health contexts
-
Proactive Risk Mitigation Through Internal Monitoring
Our findings demonstrate that internal-state-based safety inference enables proactive intervention before harmful content reaches users:
-
Pre-generation Intervention:
- The clear clustering patterns in internal representations show safety determination occurs within the model’s reasoning process, not just at output
- High confidence predictions enable immediate intervention when internal states indicate potential harm generation
- Feature-based monitoring allows real-time assessment during the generation process itself
Clinical Safety Benefits:
- Zero-exposure Protection: Users never receive harmful content, eliminating the risk window inherent in post-generation filtering
- Context-aware Safety: Internal representations capture the model’s understanding of user vulnerability and crisis indicators
- Immediate Intervention: Safety systems can trigger alternative response pathways (crisis resources, professional referrals) before harmful content generation completes
Implementation for Mental Health Applications
Crisis-aware Deployment Strategy:
- Heightened Sensitivity: Lower safety thresholds for users exhibiting crisis indicators
- Alternative Response Generation: When unsafe internals are detected, immediately redirect to verified mental health resources
- Professional Handoff Protocols: Seamless transition to human crisis counselors when internal states indicate severe risk
Real-world Impact: The well-calibrated confidence scores enable nuanced responses high-confidence harmful predictions to trigger immediate crisis protocols, while moderate-confidence cases can prompt additional safety checks or gentle redirection to appropriate resources.
Ethical Imperative: For mental health applications, the difference between reactive and proactive safety measures can be literally life-or-death. Internal-state monitoring represents not just a technical improvement, but an ethical obligation to protect vulnerable users from any exposure to potentially harmful content.
Limitations
- Sample Size: The analysis is based on a limited number of samples (5 in PCA), which may not fully represent the complexity of real-world safety scenarios
- Feature Interpretability: While I identify important features, their semantic meaning in the context of safety remains unclear
- Generalization: Results may be specific to the particular model architecture and training data used
Future Research Directions
- Mental Health-Specific Validation: Large-scale studies with mental health crisis scenarios to validate safety inference effectiveness in high-risk contexts
- Crisis Indicator Integration: Development of specialized internal features that detect user vulnerability states and crisis indicators
- Scale-up Studies: Validation with larger, more diverse datasets representing various safety scenarios across different populations
- Cross-model Validation: Testing the approach across different LLM architectures and sizes, particularly those deployed in healthcare settings
- Interpretability Enhancement: Developing methods to understand what specific safety concepts each internal feature represents, especially those relevant to mental health risks
- Dynamic Adaptation: Investigating how safety inference performance changes as models are fine-tuned or updated for mental health applications
- Clinical Integration: Partnerships with mental health professionals to validate intervention protocols and ensure seamless handoff procedures
Conclusions
This study provides compelling evidence that LLM safety responses can be effectively inferred from internal model representations, with particularly critical implications for mental health applications. The combination of:
- Clear clustering in reduced dimensional space
- Well-calibrated confidence predictions
- Identifiable high-importance features
- Practical deployment feasibility
Together demonstrate that internal-state-based safety monitoring represents a viable and promising approach for LLM safety assurance. This methodology could significantly enhance the reliability and efficiency of AI safety systems in production environments, especially in high-stakes contexts like mental health support.
Critical Contribution to Mental Health AI Safety:
The results suggest a paradigm shift from reactive to proactive safety measures. Rather than relying solely on output-based safety filtering that exposes vulnerable users to harmful content before intervention, practitioners can implement preventive safety measures by monitoring internal model states. This approach is particularly vital for mental health applications where even momentary exposure to harmful suggestions can have severe consequences for users in crisis.
The ability to catch potentially harmful content before it reaches final output generation represents not just a technical advancement, but a fundamental improvement in the ethical deployment of AI systems for vulnerable populations. This research provides the foundation for developing AI safety systems that prioritize user protection through pre-emptive intervention rather than post-hoc content moderation.